Hot
New
of
All
Image
Model
AI uygulamaları
Gönderi
Çalışma Akışı
Kullanıcı
Hot
--
对脸部等进行化妆,细节增强处理,虽然都是变漂亮,但和美颜磨皮消除细节的过程刚刚相反。相信大家也应该更喜欢这个。
zail_rel_260420
25
5
--
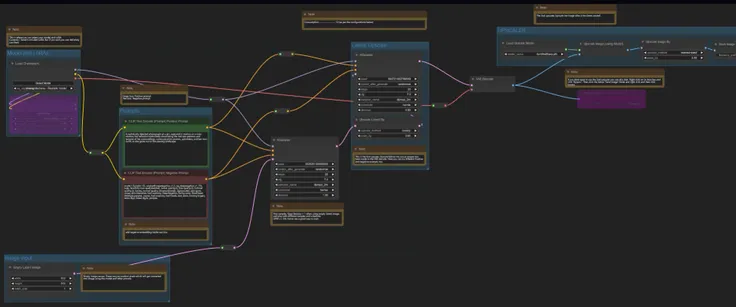
针对Animagine XL V3.1 Lora训练活动而推出的一个简易的Lora批量测试工作流,请在load Lora节点处替换待测试Lora,并调整提示词(绿色节点为正向提示词,红色节点为负向提示词)、出图大小及数量(可在Empty Latent Image节点调整)等相关参数,有相关问题可在评论区提出
NekoCat_rel_260420
0
0
5.0
Realistic photo of latina girl, sexy, 4k, high resolution, real, long hair, Generous body, beautiful curves, withe dress.
213ed7c0c23c6ce3d4f73e316c41becb
1
0
--
使用ComfyUI复现WebUI生图质量。由于ComfyUI的底层原理与WebUI的不同,因此在ComfyUI直接套用WebUI的提示词生成的图片可能质量不太好,但可以通过修改三个参数使其复现WebUI生图质量。以效率节点为例子:1、weight_interpretation(权重插值方式):comfy改为A11112、rng_source(噪声随机生成来源):cpu改为gpu3、token_normalization(token规格化):none改为mean
NekoCat_rel_260420
0
0
--
Introducing the All-Purpose Character Generator: the ultimate tool for easy character creation using your preferred LoRas. Designed to work seamlessly with any model, this efficient workflow simplifies the process of selecting models and configuring LoRas. Dive into your imagination and breathe life into characters effortlessly. Note: This workflow works best with anime-style art. But realistic images works great as well. Version: 0.3 Update for v0.3: - Added img2img capabilities - Also added openpose for the img2img if you wish to keep the pose of the input image same in the output image Update for v0.2: - Fixed the issue that was causing vertical artifacts, which was due to an issue with the negative prompt
Ghostbat101
11
3
--
Basic text to image workflow of Flux AI Model.
GrayMan_rel_260420
24
2
--
本工作流是SVD的基础模板,主要面向新手朋友。SVD是Stable Diffusion官方发布的生成式视频模型Stable Video Diffusion。只需上传一张图片,调整参数,即可生成一段几秒钟的视频。在本工作流中,上传任意尺寸图片,可生成3秒钟的长边为768像素的MP4视频,消耗约40点算力。参数讲解:基础参数(一般不用改):Width: 生成视频的宽度;Height: 生成视频的高度;尺寸最好与上传的图片一致,建议在1500以内,为了节省算力,本工作流通过缩放图片,控制在768以内。Video frames: 生成的运动总帧数,建议最大选择25帧FPS: 视频每秒刷新多少张图像,6或者8运动参数(重点修改调试):CFG: 越接近1,初始图像对画面的控制能力也就越小,建议3左右Motion bucketid: 数值越大运动幅度越大,建议100以内,不超过200Augmentation level: 添加到图像的噪声量,数值越大变化越大,建议0.1以内,不超过0.5CFG、Motion bucketid、Augmentation level要根据实际情况动态调整。
NekoCat_rel_260420
0
0
--
对脸部等进行化妆,细节增强处理,虽然都是变漂亮,但和美颜磨皮消除细节的过程刚刚相反。相信大家也应该更喜欢这个。
zail_rel_260420
0
0
--
A different approach in the space of upscaling, Rather than upscaling the final image, Latent upscaling in the middle of the process can increase the details in an image significantly. I have implemented this idea in the comfy UI workflow and made an 8K image. This workflow is very good for beginners because i have added few useful notes in it. So feel free to use it and post your work and feedback.
blackpanther69_rel_260420
1
0
--
内附详细说明的纸艺风格艺术字工作流,上传白底黑字的图片,即可生成高质量的艺术字。工作流每个环节都有说明,同时设置超分模块,默认为普通出图,可根据需要连接即可切换。
觅晨
0
0
--
海艺的XL出图点模糊,出图后用sd图生图可以清晰一点。各种风格转换。不同模型作用不同。自己更换发挥。可以在sd1.5换上自己喜欢的人物lora。两个条件控制足够了,可以更换。封面是二次元旗袍转真人。
COMG3O_rel_260420
3
1
--
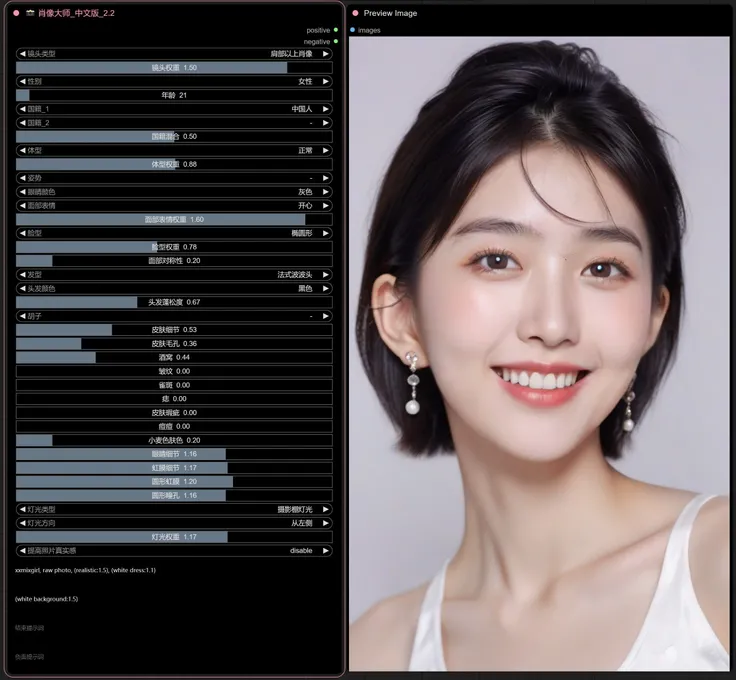
镜头类型:头像、肩部以上肖像、半身像、全身像、脸部肖像 性别:女性、男性 国籍_1:193个国家可选 国籍_2:193个国家可选 体型:瘦、正常、超重等4种 姿势:回眸、S曲线、高级时尚等18种 眼睛颜色:琥珀色、蓝色等8种 面部表情:开心、伤心、生气、惊讶、害怕等24种 脸型:椭圆形、圆形、梨形等12种 发型:法式波波头、卷发波波头、不对称剪裁等20种 头发颜色:金色、栗色、灰白混合色等9种 胡子:山羊胡、扎帕胡等20种 灯光类型:柔和环境光、日落余晖、摄影棚灯光等32种 灯光方向:上方、左侧、右下方等10种 起始提示词:写在开头的提示词 补充提示词:写在中间用于补充信息的提示词 结束提示词:写在末尾的提示词 提高照片真实感:可强化真实感 负面提示词:新增负面提示词输出
fengmi
0
0
--
面向新手,提供了五种常见的ControlNet预处理方法,帮助理解学习ControlNet的运作原理。改变最后的图片保存节点的所连节点,可获取不同的ControlNet预处理图以作二次处理。
NekoCat_rel_260420
0
0
--
文本转视频 text2vidio使用animatediff基础版本
zail_rel_260420
9
0
--
Generation of images under criteria in other image models
LK 7
0
0
--
天使与恶魔,光明与黑暗只在你一念之间。基于Animagine XL V3.1训练的lora《女武神》喜欢的可以直接访问模型页面:https://www.seaart.me/zhCN/models/detail/ce450fc103bb4a6fa575626785f4ac5e
MngYou_rel_260420
0
0
Daha Fazla