

MaskGCT,完全非自回归TTS模型,带来SOTA级零样本语音生成体验,支持多种情境的声音克隆与情绪调控。
由趣丸科技联合香港中文大学(深圳)最新开源的MaskGCT模型,通过完全非自回归设计,展现出当前领先的零样本文本到语音(TTS)技术性能。相比传统TTS模型,MaskGCT通过掩码生成模型和语音表征的解耦编码,在跨语种合成、声音克隆及语音情绪控制等方面达到新的技术高度。
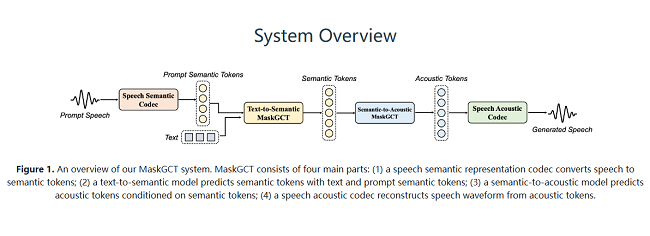
MaskGCT不仅在无训练样本情况下可以模仿各类声音,更无需音素级持续时间预测或文本与语音的精确对齐。其基于掩码预测的创新机制,让声音生成能够在节奏、语速、停顿和情绪上灵活调控,实现自然的语音生成效果。
多场景应用:零样本语音克隆及情绪控制

MaskGCT在零样本语音生成领域表现尤为出色,即便在没有针对性数据的情况下,仍可生成流畅、自然的语音。这种突破意味着用户无需额外训练数据即可模仿目标声音,不论是动画角色还是特定人物的声音都能轻松实现。此外,该模型允许用户调节生成语音的韵律、情绪和语气,支持多种情绪调控,如快乐、悲伤、愤怒及冷静等,满足个性化语音需求。
语音转换与编辑:实现声音风格的精准控制
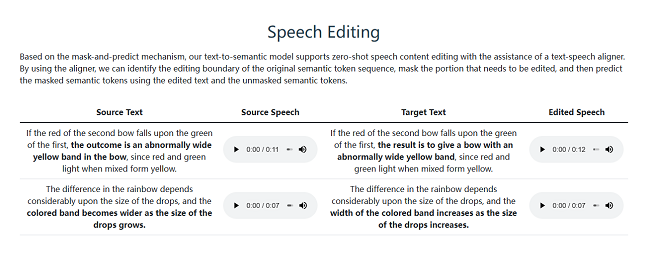
MaskGCT还支持语音转换,即将一段话用另一人的声音复述。该功能对语音克隆、音频编辑以及语音助手的个性化应用尤其适用。例如,一段话可在语音转换中保持内容一致但改变说话者的声音。通过语音编辑,用户可在掩码生成机制支持下进行精细内容调整,如屏蔽或修改特定文本片段,或在文本语音对齐器帮助下识别出编辑边界,实现零样本语音编辑功能。
语音节奏与韵律控制:调节自然的语音表现力

MaskGCT提供了全面的语音节奏控制功能,让用户得以调节生成语音的快慢、停顿等特征,以确保语音的自然度和表现力。这使用户能够定制语音节奏,确保内容表达的准确性和听感的舒适度。
跨语种语音翻译与更强的性能表现
MaskGCT还在跨语种语音合成上表现优异,通过多场景应用展示了模型的通用性。在多个评估指标上,MaskGCT均优于SOTA(如CosyVoice与XTTS-v2)。从以下表格可见其卓越表现:
- 相似度(SIM-O):在SeedTTS测试集中,MaskGCT的相似度评分接近真实语音,说明其生成的声音极具仿真性。
- 词错误率(WER):较低的WER反映了模型生成内容的准确性,在SeedTTS测试集上的表现尤为突出。
- 频谱距离(FSD):MaskGCT在FSD上的得分优于多数竞品,生成语音在音质上更接近真实人声。
- 主观评分(SMOS和CMOS):在自然度与音质主观评分中,MaskGCT得分领先,特别是在使用真实语音时长作为参考的情况下,用户体验更佳。
总结
总体而言,MaskGCT的创新技术突破与出色的性能表现,使其成为TTS领域的前沿解决方案。通过MaskGCT,AI语音生成变得更自然、灵活、富有表现力,并支持多样化的应用场景,为语音生成和语音控制提供了强大而灵活的技术支持。